
In the era of Big Data where organizations are facing the challenge of handling large volumes of diverse data, traditional data management approaches, such as data warehouses and data lakes are simply not enough. A new paradigm has emerged in this space that combines the best of both worlds – Data Lakehouse. Data lakehouse provides a unified data management architecture that blends the scalability and flexibility of data lakes with the reliability and performance of data warehouses. It aims to overcome the limitations of traditional data management approaches, providing organizations with a comprehensive solution to store, process, and analyze vast amounts of structured and unstructured data.
In this blog post, we will explore the key components of a data lakehouse, including the Medallion Architecture, Delta Tables, Data Mesh and Unity Catalog. We will also delve into the advantages that the data lakehouse brings over traditional data warehouses and data lakes.
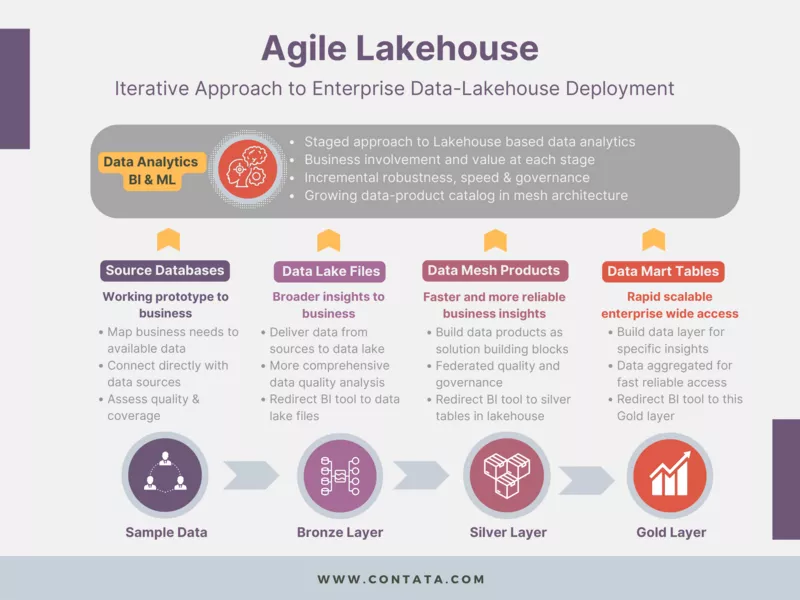
Medallion Architecture: Bronze, Silver, and Gold
Also known as the three-tier architecture, the Medallion Architecture is a central concept in the data lakehouse approach, providing a framework for organizing and managing data. It comprises three layers: Bronze, Silver, and Gold.
Bronze Layer
The Bronze Layer represents the raw data stage of the data lakehouse where the data is ingested from various sources and stored in its original format. Unlike traditional data warehouses, the Bronze Layer does not enforce strict schema definitions, allowing for the ingestion of diverse data types and formats. The focus here is on capturing and preserving the data as it is, without any modifications.
Silver Layer
The Silver Layer builds upon the raw data in the Bronze Layer and focuses on data processing and refinement. In this layer, data is cleaned, transformed, and integrated to ensure consistency and quality. Structured schemas are applied to the data, making it more accessible and easier to query and analyze. The Silver Layer acts as a staging area where data is prepared for further analysis and consumption.
Gold Layer
The Gold Layer represents the curated and refined data that is ready for consumption by end-users and applications. In this layer, data undergoes further transformations, aggregations, and enrichments to create a unified and reliable dataset. The Gold Layer is optimized for high-performance querying and analytics, providing a consolidated view of the data that is suitable for a wide range of analytical tasks.
Delta Tables: The Foundation of Data Consistency & Reliability
Delta Tables are a key component of the data lakehouse architecture. They are an open-source storage format that combines the scalability of a data lake with the reliability and consistency of a data warehouse. Delta tables are built on top of cloud object stores, such as Amazon S3 or Azure Blob Storage and provide ACID (Atomicity, Consistency, Isolation, Durability) guarantees.
Delta tables offer several features that enhance integrity and reliability of data. They support transactional operations, allowing for atomic commits and rollbacks. Additionally, Delta tables provide schema evolution capabilities, enabling the seamless evolution of data structures over time. This feature is crucial in a dynamic data environment where schemas often change to accommodate new business requirements.
Data Mesh: Protect Your Data Assets
Data Mesh is a decentralized approach to data management that emphasizes the distribution of data ownership and governance to domain teams within an organization. It advocates for treating data as a product and encourages domain teams to take responsibility for their data assets, enabling them to develop and maintain their own data products. This approach promotes scalability, agility, and collaboration, allowing organizations to leverage the expertise of domain teams and foster a culture of data-driven decision-making. By implementing Data Mesh, organizations can overcome the challenges of centralized data architectures and enable more effective and efficient data management processes.
Unity Catalog: Centralized Data Access Control
Just like data tables, unity catalog is also a critical component of the data lakehouse, providing a unified and centralized repository for managing and governing data assets. Unity catalog offers a comprehensive view of the available datasets, their metadata, and their associated attributes. It enables effective metadata management, data lineage tracking, data discovery, and access control. By leveraging unity catalog, organizations can enhance data governance, collaboration, and data quality, ultimately deriving greater value from their data within the Data Lakehouse ecosystem.
Contata’s Agile Data Lakehouse Solution: What Contata has to Offer
Contata’s agile data lakehouse solutions focus on implementing an iterative strategy to enterprise data lakehouse deployment. The goal is to help clients speed up analytics, generate reports as soon as the data is processed, and save valuable time. Following the Medallion approach, we ensure that data-driven insights and predictive models are readily available for decision-makers.
What We Do
We first ingest data from various sources and store it in the data lakehouse, preserving its raw format and ensuring flexibility for future analysis—the bronze stage. Metadata is created to catalog and index the data, making it easily discoverable and accessible for subsequent stages. Ingesting and cataloging diverse data into the data lakehouse streamlines the data integration process, eliminating the need for manual data gathering and integration efforts. This saves time and resources associated with data collection and consolidation.
Before moving data to the silver stage, we identify the new or modified data that needs to be loaded into the silver layer. We compare the incoming data with the existing data in the silver layer, using various tools such as Auto Loader. Once the changes are identified, we extract the relevant data from the source systems or the staging area where the incremental data is stored. This can involve using different extraction methods, such as using database queries, APIs, log files, or file system snapshots.
In the silver stage, we transform the raw data into a standardized and structured format, handling missing values, and removing any data quality issues. By applying data cleansing techniques and using tools like data profiling and data quality checks, we ensure the integrity and reliability of the data. Once the data is prepared, data scientists and analysts can explore it using advanced visualization tools and techniques. They can uncover patterns, correlations, and outliers within the data, gaining initial insights. This exploration helps in formulating hypotheses and identifying potential areas for deeper analysis.
In the Gold stage, we leverage the cleansed and explored data to perform advanced analytics and model development. We apply machine learning algorithms, predictive modeling, and statistical techniques to generate actionable insights for clients and drive data-driven decision-making. Businesses can respond quickly to changing customer needs, optimize resource allocation, and improve outcomes.
Reasons to Choose Contata’s Agile Data Lakehouse Solution
Scalability & Flexibility
Unlike traditional data warehouses, Contata’s agile data lakehouse solutions provide scalability and flexibility in data to handle diverse data types and volumes. The ability to store raw data in its original f management ormat allows for easy adaptation to changing data sources and structures, accommodating future growth without significant upfront modeling efforts.
Real-Time Analytics
The data lakehouse enables real-time analytics by combining the low-latency querying capabilities of a data warehouse with the ability to ingest and process streaming data. This empowers organizations to extract insights from real-time data streams, enabling faster decision-making and responsiveness.
Agility & Iterative Development
The data lakehouse supports iterative development and agile data practices. Data scientists and analysts can easily explore and experiment with raw data, apply transformations incrementally, and iterate on analytical models, resulting in faster insights and innovation.
Conclusion
The data lakehouse represents a significant evolution in data management, combining the strengths of data warehouses and data lakes while addressing their limitations. With its Medallion Architecture, Delta Tables, and Unified Catalog, the data lakehouse offers scalability, flexibility, and reliability for managing diverse data sources. By leveraging the advantages of the data lakehouse over traditional data warehouses and data lakes, organizations can unlock the true potential of their data, enable advanced analytics, and gain a competitive edge in the data-driven era.